正常自动驾驶融合摄像机图案时,会先对每个摄像头的图像预测一个距离,单目直接算深度很难且容易出错,如果先做2D检测再拼就无法端到端优化。本文尝试不用 LiDAR 的同时不显式预测深度的情况得到 BEV 特征图,分为三步:Lift Splat Shoot。
Lift:对每个图像进行单独处理,将每个图片从二维升维到三维坐标系。在单目目标检测中,一般需要先将深度转换为参考坐标系坐标,在 LSS 中则是直接为每个像素生成所有可能深度的表示。对每个像素的输出就是 $c \alpha_d$,即语义特征向量和深度概率的外积。
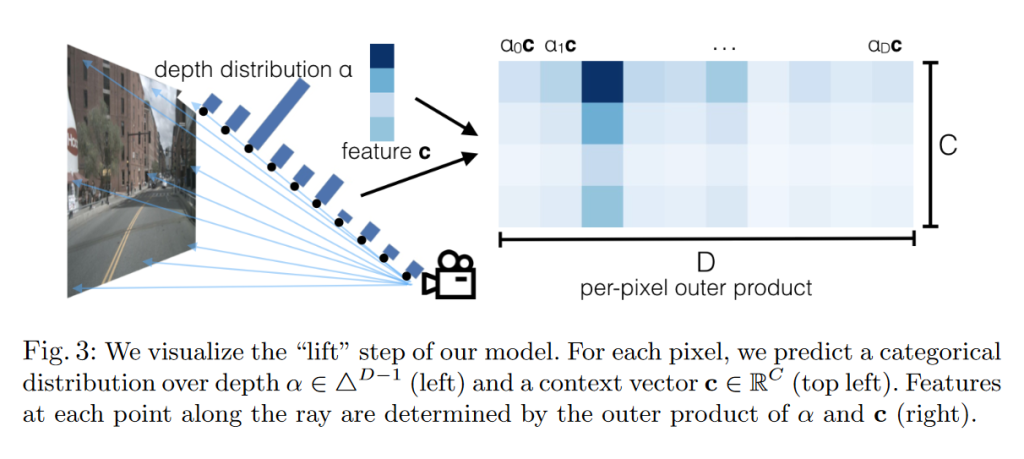
Splat:通过每个像素的 2D 坐标值和深度,以及相机的内参和外参,计算像素在车身坐标系中的 3D 坐标,忽略掉高度,计算出它属于哪个 BEV 网格单元,然后把该像素的特征加入进去。
Shoot:用 Splat 中得到的 BEV 特征图再接入一个卷积网络,来产生需要的输出。