最近 FSL 的文章看的比较少,这篇算其中之一,感觉讲的比较有意思,所以记录一下。
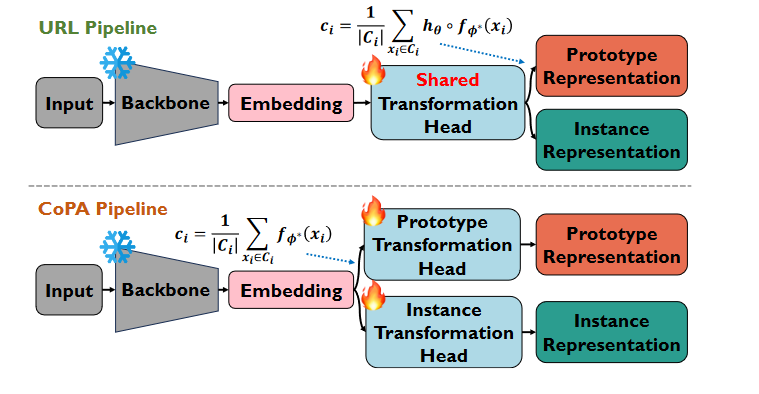
简单说就是在以往的 FSL 问题的处理方法中,用到 Prototype 的方法基本都是先将图像嵌入,然后通过一个转换头后在对同一类的图像求加权平均得到他们的 Prototype。然后在测试的时候求图像和每个 Prototype 的欧氏距离找最小的作为答案。本文中提到图像和 Prototype 不应该使用同样的转换头,因为两者并不是同一维度的信息(类似 CLIP 中的图像与文本)。因为 Prototype 实际是同一类图像的共同特征,而单个图像则有更多的独立特征,所以两者不应被一概而论。
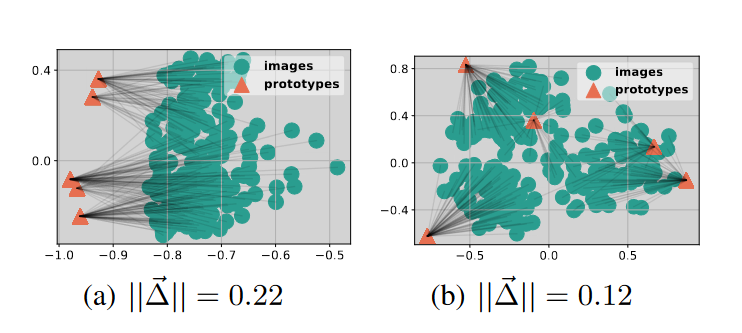
原文中的这张图表明,在嵌入后 Prototype 和图像会保持着一定的距离,在应用同一个转换头后把这种距离缩小了。正常我们会认为,这个距离越小说明聚类做的越好,分类效果越好。但是在后面作者发现并非如此。在尝试对嵌入后的分布进行适当的缩放处理后再进行训练,可以得到以下结果:
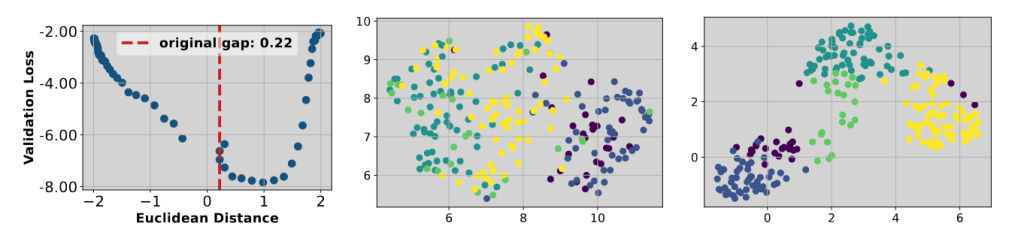
可以发现,在距离适当增大的情况,训练的 loss 才会达到最低,并不是越小越好。作者对此的解释是,距离过小会一定程度上表现的过拟合,距离略微变大才是更加适合的分布情况,有助于提升泛化能力。
所以作者提出了 COPA,即对 Prototype 和图像在嵌入后当成不同维度的信息来处理,借鉴了 CLIP 中图像和文字分别处理的想法,使用不同的转换头处理 Prototype 和图像,最后可以得到结果:
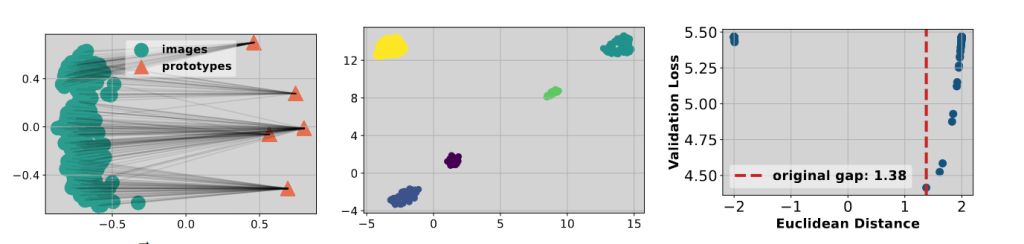
可以发现使用 COPA 后图像和 Prototype 的距离增大了,并且每一类之间也更加紧凑。同时验证损失在 COPA 学习到的间隙处达到最小值,说明这种方法可以提高泛化性能。