概括:作者发现 CLIP 里冻结的 ResNet 图像编码器,其前 4 层多尺度密集特征对噪声相对不敏感同时保持内容判别性。于是通过训练一个编码器,将带噪声的图像还原为干净图像。
CLIP 提供了两种图像编码器,ResNet 和 ViT。ResNet 通过连续的 Conv-block 和 Pooling 操作提取多尺度特征图,ViT 则是将图像分解为更小的 16$\times$16 块,然后使用标准的 Transformer进行操作。因为 ViT 方法抛弃了许多细节,所以采用 ResNet。
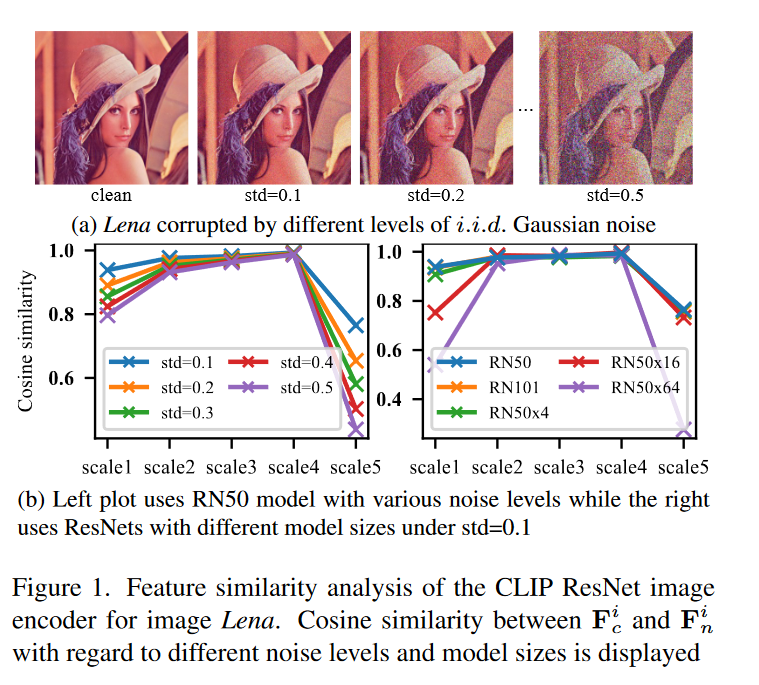
然后作者测试了在 RN50 的情况下添加不同强度的噪声以及添加 std=0.1 的噪声时不同的网络的结果(其与干净图像通过网络后的余弦相似度),可以发现通过 RN50 的前四层效果是最好的。
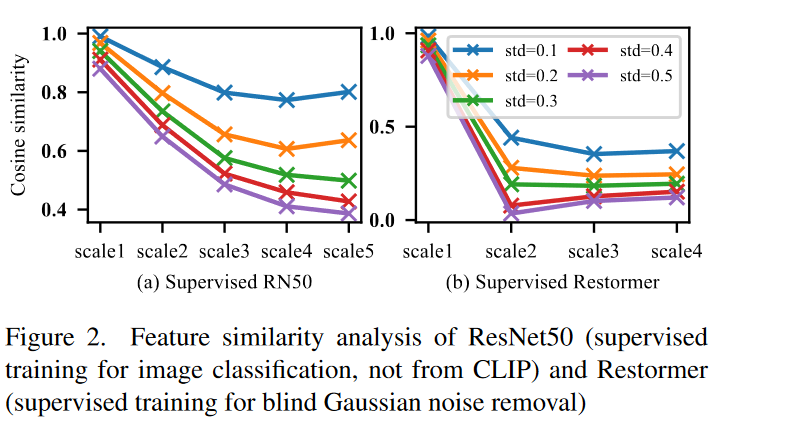
然后作者又测试了基础的监督学习 RN50 网络以及 Restormer,可以发现并不具有普适性,这种效果源自 CLIP。
使用了 t-SNE 来对数据进行降维可视化,可以发现图像内容和 CLIP RN50 的多尺度特征具有强相关性。即使加了噪声,前四尺度特征依然显著区分不同图像内容。
因为这种特性,所以作者选用 CLIP 的 RN50 Encoder 前四层作为去噪网络的第一部分,然后再通过一个可学习的 Decoder 以及 3$\times$3 的 Conv block 来还原干净图像。
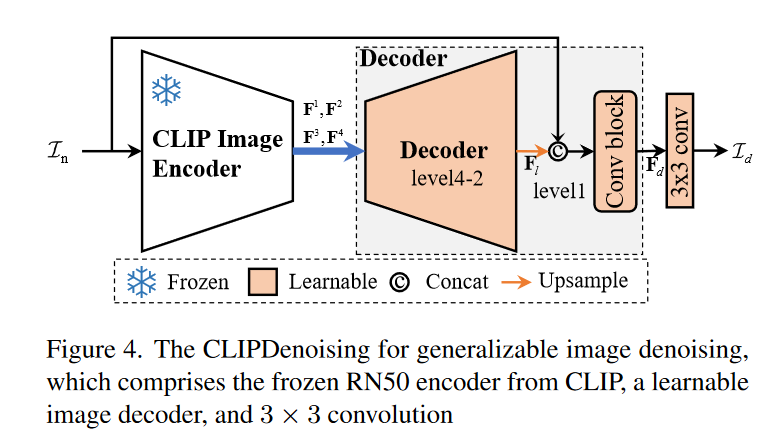
没有使用全局残差从而利用 CLIP 的特性提升去噪泛化能力。
因为第四层以后保存最多的语义信息,但是空间分辨率低,所以和带噪声但是有完整细节和纹理的图像 $I_n$ cat 到一起。
损失函数:$\mathcal{L} = \mathbb{E}_{p(\mathcal{I}_c)} |\mathcal{I}_d – \mathcal{I}_c|_1$